|
此版本仍在开发中,尚未被视为稳定版本。对于最新的稳定版本,请使用 spring-cloud-stream 4.1.4! |
分区
Spring Cloud Stream 支持在给定应用程序的多个实例之间对数据进行分区。 在分区方案中,物理通信介质(例如代理主题)被视为结构化为多个分区。 一个或多个创建者应用程序实例将数据发送到多个使用者应用程序实例,并确保由共同特征标识的数据由同一使用者实例处理。
Spring Cloud Stream 为以统一的方式实现分区处理用例提供了一个通用的抽象。 因此,无论代理本身是否自然分区(例如 Kafka)或是否(例如 RabbitMQ),都可以使用分区。
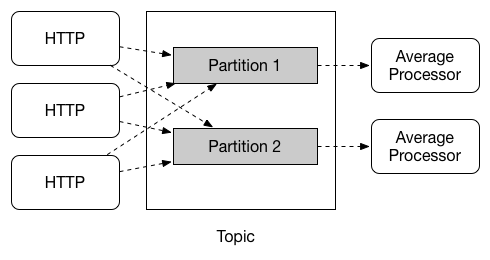
分区是有状态处理中的一个关键概念,其中确保所有相关数据一起处理至关重要(出于性能或一致性原因)。 例如,在时间窗口平均计算示例中,来自任何给定传感器的所有测量值都必须由同一应用程序实例处理,这一点很重要。
| 要设置分区处理方案,必须同时配置数据生成端和数据使用端。 |
Spring Cloud Stream 中的分区包括两个任务:
配置用于分区的输出绑定
您可以通过设置一个且仅一个其partitionKeyExpression或partitionKeyExtractorName属性及其partitionCount财产。
例如,以下是有效且典型的配置:
spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExpression=headers.id spring.cloud.stream.bindings.func-out-0.producer.partitionCount=5
根据该示例配置,使用以下逻辑将数据发送到目标分区。
对于发送到分区输出绑定的每条消息,分区键的值是根据partitionKeyExpression.
这partitionKeyExpression是针对出站消息计算的 SPEL 表达式(在前面的示例中,它是idfrom message headers) 提取分区键。
如果 SPEL 表达式不足以满足您的需求,则可以改为通过提供org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy并将其配置为 Bean(通过使用@Bean注释)。
如果您有多个类型的 beanorg.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy中,您可以通过使用partitionKeyExtractorName属性,如以下示例所示:
--spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExtractorName=customPartitionKeyExtractor
--spring.cloud.stream.bindings.func-out-0.producer.partitionCount=5
. . .
@Bean
public CustomPartitionKeyExtractorClass customPartitionKeyExtractor() {
return new CustomPartitionKeyExtractorClass();
}在早期版本的 Spring Cloud Stream 中,您可以指定org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy通过设置spring.cloud.stream.bindings.output.producer.partitionKeyExtractorClass财产。
从版本 3.0 开始,此属性已删除。 |
计算出消息键后,分区选择过程会将目标分区确定为0和partitionCount - 1.
适用于大多数方案的默认计算基于以下公式:key.hashCode() % partitionCount.
这可以在绑定上自定义,方法是将 SPEL 表达式设置为针对“键”进行评估(通过partitionSelectorExpression属性),或者通过配置org.springframework.cloud.stream.binder.PartitionSelectorStrategy作为 Bean (通过使用 @Bean 注解)。
与PartitionKeyExtractorStrategy,您可以使用spring.cloud.stream.bindings.output.producer.partitionSelectorName属性,如以下示例所示:
--spring.cloud.stream.bindings.func-out-0.producer.partitionSelectorName=customPartitionSelector
. . .
@Bean
public CustomPartitionSelectorClass customPartitionSelector() {
return new CustomPartitionSelectorClass();
}在早期版本的 Spring Cloud Stream 中,您可以指定org.springframework.cloud.stream.binder.PartitionSelectorStrategy通过设置spring.cloud.stream.bindings.output.producer.partitionSelectorClass财产。
从版本 3.0 开始,此属性已删除。 |
配置用于分区的输入绑定
输入绑定(带有绑定名称uppercase-in-0) 配置为接收分区数据,方法是将其partitionedproperty 以及instanceIndex和instanceCountproperties 上,如以下示例所示:
spring.cloud.stream.bindings.uppercase-in-0.consumer.partitioned=true spring.cloud.stream.instanceIndex=3 spring.cloud.stream.instanceCount=5
这instanceCountvalue 表示应在其之间对数据进行分区的应用程序实例的总数。
这instanceIndex必须是多个实例中的唯一值,值介于0和instanceCount - 1.
实例索引可帮助每个应用程序实例识别它从中接收数据的唯一分区。
使用本身不支持分区的技术的 Binders 需要它。
例如,使用 RabbitMQ 时,每个分区都有一个队列,队列名称包含实例索引。
使用 Kafka 时,如果autoRebalanceEnabled是true(默认)时,Kafka 负责在实例之间分配分区,并且这些属性不是必需的。
如果autoRebalanceEnabled设置为 false 时,instanceCount和instanceIndex被 Binder 用于确定实例订阅的分区(您的分区数必须至少与实例数一样多)。
Binder 分配分区而不是 Kafka。
如果您希望特定分区的消息始终发送到同一实例,这可能很有用。
当 Binder 配置需要它们时,正确设置这两个值非常重要,以确保所有数据都被使用,并且应用程序实例接收互斥的数据集。
虽然使用多个实例进行分区数据处理的场景在独立情况下设置可能很复杂,但 Spring Cloud Dataflow 可以通过正确填充输入和输出值并让您依赖运行时基础设施提供有关实例索引和实例计数的信息来显着简化该过程。