配置和运行作业
配置和运行作业
在 domain 部分 ,总体 讨论了架构设计,使用下图作为 指导:
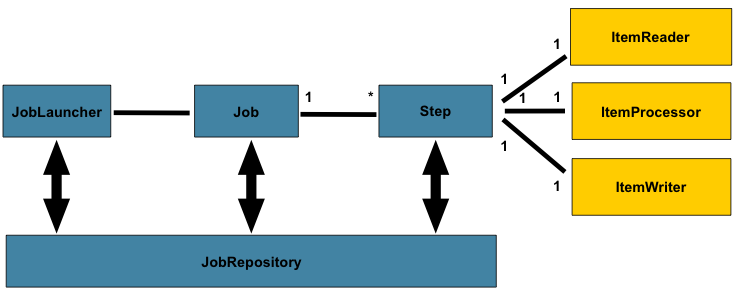
虽然Jobobject 可能看起来像一个简单的
容器中,您必须了解许多配置选项。
此外,您必须考虑许多关于
如何Job可以运行,以及其元数据如何
在该运行期间存储。本章介绍各种配置
options 和 runtime 关注点Job.
配置 Job
有多种Job接口。然而
构建器抽象出配置中的差异。
以下示例创建一个footballJob:
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.build();
}
一个Job(通常,任何Step)需要一个JobRepository.这
的配置JobRepository通过Java Configuration.
前面的示例说明了Job由三个Step实例。工作相关
构建器还可以包含其他有助于并行化的元素 (Split),
声明式流控制 (Decision)和流定义的外部化 (Flow).
有多种Job接口。但是,命名空间抽象出了配置中的差异。它有
只有三个必需的依赖项:名称、JobRepository和Step实例。
以下示例创建一个footballJob:
<job id="footballJob">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s2" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
</job>此处的示例使用父 Bean 定义来创建步骤。
请参阅 步骤配置 部分,了解内联声明特定步骤详细信息时的更多选项。XML 命名空间
默认引用 ID 为jobRepository哪
是合理的默认值。但是,您可以显式覆盖它:
<job id="footballJob" job-repository="specialRepository">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s3" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
</job>除了步骤之外,作业配置还可以包含其他有助于
并行化 (<split>)、声明式流控制 (<decision>) 和外部化
流定义 (<flow/>).
可重启性
执行批处理作业时的一个关键问题涉及Job当它是
重新 启动。推出Job如果JobExecution已存在特定的JobInstance.理想情况下,所有作业都应该能够启动
从他们离开的地方开始,但在某些情况下这是不可能的。在这种情况下,完全由开发人员来确保新的JobInstance已创建。但是,Spring Batch 确实提供了一些帮助。如果Job永远不应该是
重新启动,但应始终作为新的JobInstance中,您可以设置
restartable 属性设置为false.
以下示例演示如何设置restartablefield 设置为false在 XML 中:
<job id="footballJob" restartable="false">
...
</job>以下示例演示如何设置restartablefield 设置为false在 Java 中:
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.preventRestart()
...
.build();
}
换句话说,设置restartable自false意思是“这个Job不支持再次启动”。重新启动Job那不是
restartable 会导致JobRestartException自
被扔掉。
以下 Junit 代码会导致引发异常:
Job job = new SimpleJob();
job.setRestartable(false);
JobParameters jobParameters = new JobParameters();
JobExecution firstExecution = jobRepository.createJobExecution(job, jobParameters);
jobRepository.saveOrUpdate(firstExecution);
try {
jobRepository.createJobExecution(job, jobParameters);
fail();
}
catch (JobRestartException e) {
// expected
}
第一次尝试创建JobExecution对于不可重新启动的
job 不会引起任何问题。然而,第二个
尝试抛出JobRestartException.
拦截任务执行
在执行Job,收到各种
事件,以便可以运行自定义代码。SimpleJob允许通过调用JobListener在适当的时候:
public interface JobExecutionListener {
void beforeJob(JobExecution jobExecution);
void afterJob(JobExecution jobExecution);
}
您可以添加JobListeners更改为SimpleJob通过在作业上设置 listeners 来执行。
以下示例演示如何将侦听器元素添加到 XML 作业定义中:
<job id="footballJob">
<step id="playerload" parent="s1" next="gameLoad"/>
<step id="gameLoad" parent="s2" next="playerSummarization"/>
<step id="playerSummarization" parent="s3"/>
<listeners>
<listener ref="sampleListener"/>
</listeners>
</job>以下示例说明如何将侦听器方法添加到 Java 作业定义中:
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.listener(sampleListener())
...
.build();
}
请注意,afterJob无论成功与
失败Job.如果需要确定成功或失败,可以获取该信息
从JobExecution:
public void afterJob(JobExecution jobExecution){
if (jobExecution.getStatus() == BatchStatus.COMPLETED ) {
//job success
}
else if (jobExecution.getStatus() == BatchStatus.FAILED) {
//job failure
}
}
与此接口对应的注解是:
-
@BeforeJob -
@AfterJob
从父作业继承
如果一组 Job 具有相似但不相似的
相同的配置,则定义 “parent” 可能会有所帮助Job从中得到混凝土Job实例可以继承属性。与 class 相似
继承,一个 “child”Job结合
它的元素和属性与父级的 Elements 和 Attributes 一起使用。
在以下示例中,baseJob是一个抽象Job定义,仅定义
听众。这Job (job1) 是具体的
继承侦听器列表的定义baseJob和合并
it 使用自己的侦听器列表来生成Job具有 2 个侦听器和 1 个Step (step1).
<job id="baseJob" abstract="true">
<listeners>
<listener ref="listenerOne"/>
<listeners>
</job>
<job id="job1" parent="baseJob">
<step id="step1" parent="standaloneStep"/>
<listeners merge="true">
<listener ref="listenerTwo"/>
<listeners>
</job>请参阅 从父步骤继承 有关更多详细信息的部分。
JobParametersValidator (作业参数验证器)
在 XML 命名空间中声明的作业或使用AbstractJob可以选择性地为 Job 参数声明一个验证器
运行。例如,当您需要断言作业
启动其所有必需参数。有一个DefaultJobParametersValidator可用于约束组合
简单的强制和可选参数。对于更复杂的
constraints,您可以自行实现接口。
验证器的配置是通过 XML 命名空间通过子 元素,如下例所示:
<job id="job1" parent="baseJob3">
<step id="step1" parent="standaloneStep"/>
<validator ref="parametersValidator"/>
</job>您可以将验证器指定为引用(如前所述)或嵌套 Bean
定义在beansNamespace。
验证器的配置通过 Java 构建器支持:
@Bean
public Job job1(JobRepository jobRepository) {
return new JobBuilder("job1", jobRepository)
.validator(parametersValidator())
...
.build();
}
Java 配置
Spring 3 带来了使用 Java 而不是 XML 配置应用程序的能力。截至
Spring Batch 2.2.0 中,您可以使用相同的 Java 配置来配置批处理作业。
基于 Java 的配置有三个组件:@EnableBatchProcessingannotation 和 two builders。
这@EnableBatchProcessingannotation 的工作方式与其他@Enable*annotations 中的
Spring 家族。在这种情况下,@EnableBatchProcessing提供
构建批处理作业。在此基本配置中,StepScope和JobScope是
created,此外还有许多 bean 可用于 autowired:
-
JobRepository:一个名为jobRepository -
JobLauncher:一个名为jobLauncher -
JobRegistry:一个名为jobRegistry -
JobExplorer:一个名为jobExplorer -
JobOperator:一个名为jobOperator
默认实现提供前面列表中提到的 bean,并且需要一个DataSource以及PlatformTransactionManager作为上下文中的 bean 提供。数据源和交易
manager 被JobRepository和JobExplorer实例。默认情况下,名为dataSource以及名为transactionManager将被使用。您可以使用
的@EnableBatchProcessing注解。以下示例演示如何提供
自定义数据源和事务管理器:
@Configuration
@EnableBatchProcessing(dataSourceRef = "batchDataSource", transactionManagerRef = "batchTransactionManager")
public class MyJobConfiguration {
@Bean
public DataSource batchDataSource() {
return new EmbeddedDatabaseBuilder().setType(EmbeddedDatabaseType.HSQL)
.addScript("/org/springframework/batch/core/schema-hsqldb.sql")
.generateUniqueName(true).build();
}
@Bean
public JdbcTransactionManager batchTransactionManager(DataSource dataSource) {
return new JdbcTransactionManager(dataSource);
}
@Bean
public Job job(JobRepository jobRepository) {
return new JobBuilder("myJob", jobRepository)
//define job flow as needed
.build();
}
}
只有一个配置类需要具有@EnableBatchProcessing注解。一次
你有一个用它注释的类,你有前面描述的所有配置。 |
从 v5.0 开始,配置基本 infrastrucutre bean 的另一种编程方式
通过DefaultBatchConfiguration类。此类提供相同的 bean
提供方@EnableBatchProcessing,并可用作配置批处理作业的基类。
以下代码片段是如何使用它的典型示例:
@Configuration
class MyJobConfiguration extends DefaultBatchConfiguration {
@Bean
public Job job(JobRepository jobRepository) {
return new JobBuilder("job", jobRepository)
// define job flow as needed
.build();
}
}
数据源和事务管理器将从应用程序上下文中解析 并在 Job repository 和 Job Explorer 上进行设置。您可以自定义配置 通过覆盖所需的 setter 来获取。以下示例 演示如何自定义字符编码,例如:
@Configuration
class MyJobConfiguration extends DefaultBatchConfiguration {
@Bean
public Job job(JobRepository jobRepository) {
return new JobBuilder("job", jobRepository)
// define job flow as needed
.build();
}
@Override
protected Charset getCharset() {
return StandardCharsets.ISO_8859_1;
}
}
@EnableBatchProcessing不应与DefaultBatchConfiguration.您应该
要么使用声明式方式配置 Spring Batch 通过@EnableBatchProcessing,
或者使用编程方式扩展DefaultBatchConfiguration,但不能双向
同一时间。 |
配置 JobRepository
使用@EnableBatchProcessing一个JobRepository为您提供。
本节介绍如何配置您自己的
如前所述,JobRepository用于各种持久化
domain 对象,例如JobExecution和StepExecution.
许多主要框架功能都需要它,例如JobLauncher,Job和Step.
batch 命名空间抽象出JobRepository实施及其协作者。但是,仍然有一些
可用的配置选项,如下例所示:
<job-repository id="jobRepository"
data-source="dataSource"
transaction-manager="transactionManager"
isolation-level-for-create="SERIALIZABLE"
table-prefix="BATCH_"
max-varchar-length="1000"/>除了id,则前面列出的任何配置选项都不是必需的。如果他们是
未设置,则使用前面显示的默认值。
这max-varchar-length默认为2500,即长VARCHAR示例架构中的列
脚本。
除了dataSource和transactionManager,则前面列出的任何配置选项都不是必需的。
如果未设置,则前面显示的默认值
使用。这
麦克斯varcharlength 默认为2500,即
长VARCHAR示例架构脚本中的列
JobRepository 的事务配置
如果命名空间或提供的FactoryBean,交易建议是
围绕存储库自动创建。这是为了确保批处理元数据
包括失败后重新启动所需的状态将正确保留。
如果存储库方法不是
事务。的create*method attributes 的
以确保在启动作业时,如果两个进程尝试启动
同一时间执行相同的作业,只有一个成功。该
method 为SERIALIZABLE,这是相当激进的。READ_COMMITTED通常效果相同
井。READ_UNCOMMITTED如果两个进程在此中不太可能发生冲突,则很好
道路。但是,由于对create*方法相当短,则不太可能SERIALIZED会导致问题,只要数据库平台支持它。但是,您
可以覆盖此设置。
以下示例演示如何在 XML 中覆盖隔离级别:
<job-repository id="jobRepository"
isolation-level-for-create="REPEATABLE_READ" />以下示例演示如何在 Java 中覆盖隔离级别:
@Configuration
@EnableBatchProcessing(isolationLevelForCreate = "ISOLATION_REPEATABLE_READ")
public class MyJobConfiguration {
// job definition
}
如果未使用命名空间,则还必须配置 使用 AOP 的存储库的事务行为。
以下示例显示如何配置存储库的事务行为 在 XML 中:
<aop:config>
<aop:advisor
pointcut="execution(* org.springframework.batch.core..*Repository+.*(..))"/>
<advice-ref="txAdvice" />
</aop:config>
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="*" />
</tx:attributes>
</tx:advice>您可以几乎按原样使用前面的 fragment,几乎不需要任何更改。还要记住
包含适当的命名空间声明,并确保spring-tx和spring-aop(或整个 Spring)都在 Classpath 上。
以下示例显示如何配置存储库的事务行为 在 Java 中:
@Bean
public TransactionProxyFactoryBean baseProxy() {
TransactionProxyFactoryBean transactionProxyFactoryBean = new TransactionProxyFactoryBean();
Properties transactionAttributes = new Properties();
transactionAttributes.setProperty("*", "PROPAGATION_REQUIRED");
transactionProxyFactoryBean.setTransactionAttributes(transactionAttributes);
transactionProxyFactoryBean.setTarget(jobRepository());
transactionProxyFactoryBean.setTransactionManager(transactionManager());
return transactionProxyFactoryBean;
}
更改表前缀
的另一个可修改属性JobRepository是元数据的表前缀
表。默认情况下,它们都以BATCH_.BATCH_JOB_EXECUTION和BATCH_STEP_EXECUTION是两个例子。但是,有一些潜在的原因需要修改它
前缀。如果需要在表名前面加上架构名称,或者如果有多个
的元数据表集,则表前缀需要
被更改。
以下示例演示如何更改 XML 中的表前缀:
<job-repository id="jobRepository"
table-prefix="SYSTEM.TEST_" />以下示例演示如何在 Java 中更改表前缀:
@Configuration
@EnableBatchProcessing(tablePrefix = "SYSTEM.TEST_")
public class MyJobConfiguration {
// job definition
}
鉴于上述更改,对元数据表的每个查询都带有SYSTEM.TEST_.BATCH_JOB_EXECUTION称为SYSTEM.TEST_JOB_EXECUTION.
| 只有表前缀是可配置的。table 和 column name 不是。 |
存储库中的非标准数据库类型
如果您使用的数据库平台不在受支持平台列表中,则
如果 SQL 变体足够接近,则可能能够使用支持的类型之一。待办事项
this,您可以使用 RAWJobRepositoryFactoryBean而不是命名空间快捷方式和
使用它来将 Database type (数据库类型) 设置为最接近的匹配项。
以下示例演示如何使用JobRepositoryFactoryBean设置数据库类型
到 XML 中最接近的匹配项:
<bean id="jobRepository" class="org...JobRepositoryFactoryBean">
<property name="databaseType" value="db2"/>
<property name="dataSource" ref="dataSource"/>
</bean>以下示例演示如何使用JobRepositoryFactoryBean设置数据库类型
到 Java 中最接近的匹配项:
@Bean
public JobRepository jobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setDatabaseType("db2");
factory.setTransactionManager(transactionManager);
return factory.getObject();
}
如果未指定数据库类型,则JobRepositoryFactoryBean尝试
从DataSource.
平台之间的主要区别是
主要由递增主键的策略负责,因此
通常需要覆盖incrementerFactory以及(通过使用标准的
来自 Spring Framework 的实现)。
如果这不起作用,或者您没有使用 RDBMS,则
唯一的选项可能是实现各种Dao接口,该接口的SimpleJobRepository取决于
on 上,并以正常的 Spring 方式手动连接一个。
配置 JobLauncher
当您使用@EnableBatchProcessing一个JobRegistry为您提供。
本节介绍如何配置您自己的
最基本的JobLauncherinterface 是TaskExecutorJobLauncher.
它唯一需要的依赖项是JobRepository(需要执行)。
以下示例显示了TaskExecutorJobLauncher在 XML 中:
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.TaskExecutorJobLauncher">
<property name="jobRepository" ref="jobRepository" />
</bean>以下示例显示了TaskExecutorJobLauncher在 Java 中:
...
@Bean
public JobLauncher jobLauncher() throws Exception {
TaskExecutorJobLauncher jobLauncher = new TaskExecutorJobLauncher();
jobLauncher.setJobRepository(jobRepository);
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
...
获取 JobExecution 后,它会传递给
execute 方法Job,最终返回JobExecution作为
下图显示了:
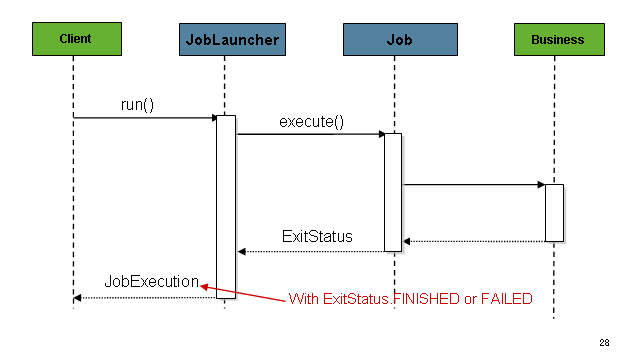
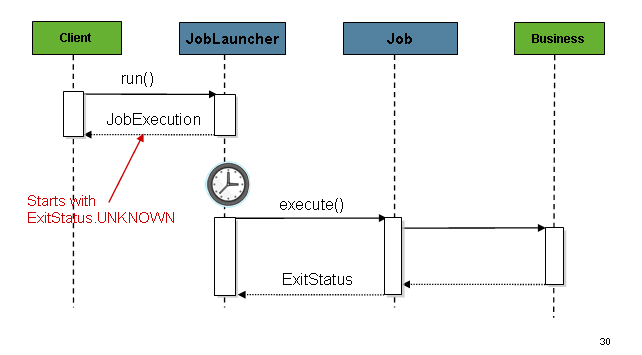
该序列简单明了,从计划程序启动时效果很好。然而
尝试从 HTTP 请求启动时出现问题。在这种情况下,启动
需要异步完成,以便TaskExecutorJobLauncher立即返回到其
访客。这是因为让 HTTP 请求保持打开状态并不是一个好的做法。
长时间运行的进程(如批处理作业)所需的时间。下图显示了
示例序列:
您可以配置TaskExecutorJobLauncher要允许这种情况,请配置TaskExecutor.
以下 XML 示例配置了TaskExecutorJobLauncher要立即返回:
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.TaskExecutorJobLauncher">
<property name="jobRepository" ref="jobRepository" />
<property name="taskExecutor">
<bean class="org.springframework.core.task.SimpleAsyncTaskExecutor" />
</property>
</bean>以下 Java 示例配置了TaskExecutorJobLauncher要立即返回:
@Bean
public JobLauncher jobLauncher() {
TaskExecutorJobLauncher jobLauncher = new TaskExecutorJobLauncher();
jobLauncher.setJobRepository(jobRepository());
jobLauncher.setTaskExecutor(new SimpleAsyncTaskExecutor());
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
你可以使用 spring 的任何实现TaskExecutor用于控制作业异步方式的接口
执行。
运行 Job
启动批处理作业至少需要两件事:Job启动,并且JobLauncher.两者都可以包含在同一个
context 或不同的上下文。例如,如果您从
命令行中,将为每个Job.因此,每个
Job 有自己的JobLauncher.但是,如果
您可以从 Web 容器中运行,该容器位于HttpRequest,通常有一个JobLauncher(针对异步作业配置
launching),多个请求调用以启动其作业。
从命令行运行 Job
如果要从企业运行作业
scheduler 中,命令行是主界面。这是因为
大多数调度器(Quartz 除外,除非使用NativeJob) 直接与作系统配合使用
进程,主要由 shell 脚本启动。有很多方法
启动除 shell 脚本之外的 Java 进程,例如 Perl、Ruby 或
甚至构建工具,例如 Ant 或 Maven。但是,因为大多数人
熟悉 shell 脚本,本示例重点介绍它们。
The CommandLineJobRunner
因为启动作业的脚本必须启动 Java
Virtual Machine 中,需要有一个具有main行动方法
作为主要入口点。Spring Batch 提供了一个实现
,用于以下目的:CommandLineJobRunner.注意
这只是引导应用程序的一种方式。有
启动 Java 进程的方法有很多种,这个类绝不应该是
被视为确定的。这CommandLineJobRunner执行四项任务:
-
加载适当的
ApplicationContext. -
将命令行参数解析为
JobParameters. -
根据参数找到合适的作业。
-
使用
JobLauncher在应用程序上下文中提供以启动作业。
所有这些任务都只需传入参数即可完成。 下表描述了所需的参数:
|
XML 文件的位置,用于
创建一个 |
|
要运行的作业的名称。 |
必须传入这些参数,路径在前,名称在后。所有参数
在这些参数被视为作业参数后,将转换为JobParameters对象
,并且必须采用name=value.
以下示例显示了作为作业参数传递给 XML 中定义的作业的日期:
<bash$ java CommandLineJobRunner endOfDayJob.xml endOfDay schedule.date=2007-05-05,java.time.LocalDate以下示例显示了作为作业参数传递给 Java 中定义的作业的日期:
<bash$ java CommandLineJobRunner io.spring.EndOfDayJobConfiguration endOfDay schedule.date=2007-05-05,java.time.LocalDate|
默认情况下, 在以下示例中, 您可以通过使用自定义 |
在大多数情况下,您需要使用 manifest 来声明main类。然而
为简单起见,该类被直接使用。此示例使用EndOfDay来自 Batch 的域语言的示例。第一个
argument 是endOfDayJob.xml,它是 Spring ApplicationContext,其中包含Job.第二个参数endOfDay,表示作业名称。最后一个参数schedule.date=2007-05-05,java.time.LocalDate转换为JobParameterObject 类型的java.time.LocalDate.
以下示例显示了endOfDay在 XML 中:
<job id="endOfDay">
<step id="step1" parent="simpleStep" />
</job>
<!-- Launcher details removed for clarity -->
<beans:bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.TaskExecutorJobLauncher" />在大多数情况下,您需要使用 manifest 来声明main类。然而
为简单起见,该类被直接使用。此示例使用EndOfDay来自 Batch 的域语言的示例。第一个
argument 是io.spring.EndOfDayJobConfiguration,这是完全限定的类名
添加到包含 Job 的配置类中。第二个参数endOfDay代表
作业名称。最后一个参数schedule.date=2007-05-05,java.time.LocalDate,已转换
转换为JobParameterObject 类型的java.time.LocalDate.
以下示例显示了endOfDay在 Java 中:
@Configuration
@EnableBatchProcessing
public class EndOfDayJobConfiguration {
@Bean
public Job endOfDay(JobRepository jobRepository, Step step1) {
return new JobBuilder("endOfDay", jobRepository)
.start(step1)
.build();
}
@Bean
public Step step1(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("step1", jobRepository)
.tasklet((contribution, chunkContext) -> null, transactionManager)
.build();
}
}
前面的示例过于简单,因为
通常在 Spring Batch 中运行批处理作业,但它用于显示两个主要的
的要求CommandLineJobRunner:Job和JobLauncher.
退出代码
从命令行启动批处理作业时,企业
经常使用 scheduler。大多数调度程序都相当愚蠢,只能工作
在流程级别。这意味着他们只知道一些
作系统进程(例如它们调用的 shell 脚本)。
在这种情况下,与调度程序通信的唯一方法
关于作业的成功或失败是通过返回代码。一个
return code 是进程返回给调度程序的数字
以指示运行结果。在最简单的情况下,0 是
成功,1 是失败。但是,可能还有更复杂的
场景,例如“如果作业 A 返回 4,则启动作业 B,如果作业返回 5,则启动作业 B
下班 C。这种类型的行为在调度程序级别配置,
但重要的是,像 Spring Batch 这样的处理框架
提供一种方法来返回退出代码的数字表示形式
对于特定的批处理作业。在 Spring Batch 中,这是封装的
在ExitStatus,其中介绍了更多
详情见第 5 章。为了讨论退出代码,
唯一需要知道的是,ExitStatus具有 exit code 属性,该属性为
设置,并作为JobExecution从JobLauncher.这CommandLineJobRunner转换此字符串值
替换为一个数字ExitCodeMapper接口:
public interface ExitCodeMapper {
public int intValue(String exitCode);
}
一个ExitCodeMapper是那个,给定一个字符串 exit
code 时,将返回一个数字表示形式。默认的
Job Runner 使用的实现是SimpleJvmExitCodeMapper,则返回 0 表示完成,1 表示一般错误,2 表示任何作业
运行器错误,例如找不到Job在提供的上下文中。如果有更多
complex 的 3 个值,则自定义
实现ExitCodeMapper接口
必须提供。因为CommandLineJobRunner是创建
一ApplicationContext因此,不能
'wired together' 时,任何需要覆盖的值都必须是
自动装配。这意味着,如果ExitCodeMapper位于BeanFactory,
在创建上下文后,它会注入到 Runner 中。都
这需要提供你自己的ExitCodeMapper是声明 implementation
作为根级 Bean 进行,并确保它是ApplicationContext由
跑步者。
从 Web 容器中运行作业
从历史上看,离线处理(例如批处理作业)一直是
从命令行启动,如前所述。但是,有
在许多情况下,从HttpRequest是
一个更好的选择。许多此类用例包括报告、临时作业
running 和 Web 应用程序支持。因为批处理作业(根据定义)
运行时间长,最关心的是启动
job 异步:
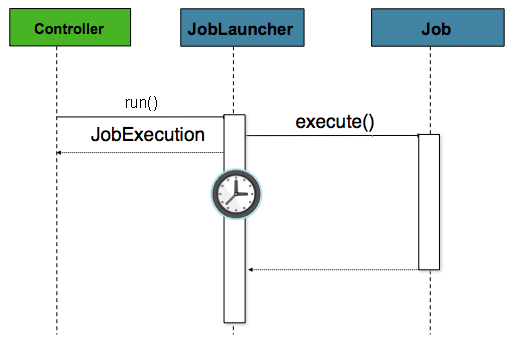
在这种情况下,控制器是 Spring MVC 控制器。请参阅
Spring Framework 参考指南,了解有关 Spring MVC 的更多信息。
控制器会启动Job通过使用JobLauncher已配置为异步启动,该
立即返回一个JobExecution.这Job可能仍在运行。但是,此
非阻塞行为允许控制器立即返回,这
在处理HttpRequest.以下清单
显示了一个例子:
@Controller
public class JobLauncherController {
@Autowired
JobLauncher jobLauncher;
@Autowired
Job job;
@RequestMapping("/jobLauncher.html")
public void handle() throws Exception{
jobLauncher.run(job, new JobParameters());
}
}
高级元数据用法
到目前为止,JobLauncher和JobRepositoryinterfaces 已被
讨论。它们共同代表了 Job 和 Basic 的简单启动
批处理域对象的 CRUD作:
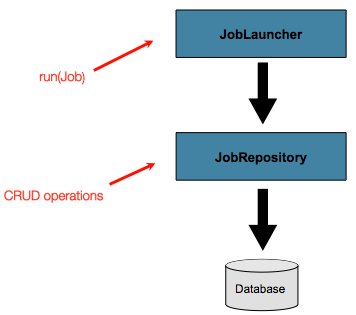
一个JobLauncher使用JobRepository新建JobExecution对象并运行它们。Job和Step实现
later use same (稍后使用相同的JobRepository对于基本更新
在Job.
基本作足以满足简单的场景。但是,在大批量
具有数百个批处理作业和复杂调度的环境
要求,则需要对元数据进行更高级的访问:
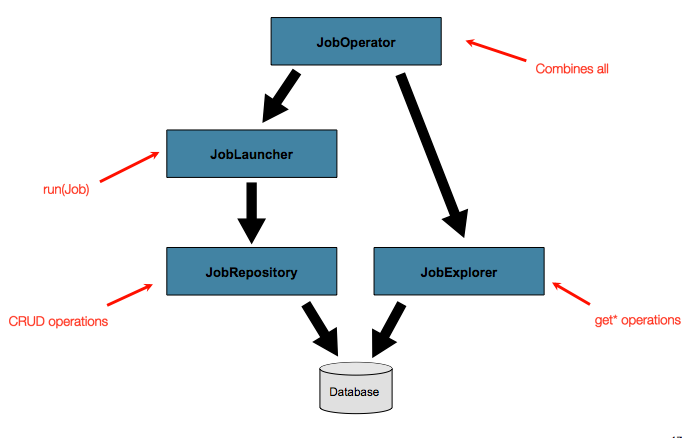
这JobExplorer和JobOperator接口,将对此进行讨论
在接下来的部分中,添加用于查询和控制元数据的其他功能。
查询存储库
在任何高级功能之前,最基本的需求是能够
查询存储库中的现有执行。此功能是
由JobExplorer接口:
public interface JobExplorer {
List<JobInstance> getJobInstances(String jobName, int start, int count);
JobExecution getJobExecution(Long executionId);
StepExecution getStepExecution(Long jobExecutionId, Long stepExecutionId);
JobInstance getJobInstance(Long instanceId);
List<JobExecution> getJobExecutions(JobInstance jobInstance);
Set<JobExecution> findRunningJobExecutions(String jobName);
}
从其方法签名中可以明显看出,JobExplorer是 的只读版本
这JobRepository和JobRepository,它可以通过使用
工厂 Bean 的 Bean 中。
以下示例显示如何配置JobExplorer在 XML 中:
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:dataSource-ref="dataSource" />以下示例显示如何配置JobExplorer在 Java 中:
...
// This would reside in your DefaultBatchConfiguration extension
@Bean
public JobExplorer jobExplorer() throws Exception {
JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
factoryBean.setDataSource(this.dataSource);
return factoryBean.getObject();
}
...
在本章的前面部分,我们注意到您可以修改表前缀
的JobRepository以允许不同的版本或架构。因为
这JobExplorer适用于相同的表,它还需要能够设置前缀。
以下示例显示如何为JobExplorer在 XML 中:
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:tablePrefix="SYSTEM."/>以下示例显示如何为JobExplorer在 Java 中:
...
// This would reside in your DefaultBatchConfiguration extension
@Bean
public JobExplorer jobExplorer() throws Exception {
JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
factoryBean.setDataSource(this.dataSource);
factoryBean.setTablePrefix("SYSTEM.");
return factoryBean.getObject();
}
...
JobRegistry (作业注册表)
一个JobRegistry(及其父接口JobLocator) 不是必需的,但可以是
如果要跟踪上下文中可用的作业,则很有用。它也是
在创建作业时,用于在应用程序上下文中集中收集作业
其他位置(例如,在子上下文中)。您也可以使用自定义JobRegistry实现
作已注册作业的名称和其他属性。
框架只提供了一个实现,它基于一个简单的
从 Job Name 映射到 Job Instance。
以下示例显示了如何包含JobRegistry对于在 XML 中定义的作业:
<bean id="jobRegistry" class="org.springframework.batch.core.configuration.support.MapJobRegistry" />使用@EnableBatchProcessing一个JobRegistry为您提供。
以下示例显示如何配置您自己的JobRegistry:
...
// This is already provided via the @EnableBatchProcessing but can be customized via
// overriding the bean in the DefaultBatchConfiguration
@Override
@Bean
public JobRegistry jobRegistry() throws Exception {
return new MapJobRegistry();
}
...
您可以填充JobRegistry通过以下两种方式之一:使用
Bean 后处理器或使用 registrar 生命周期组件。即将来临
各节介绍了这两种机制。
JobRegistryBeanPostProcessor
这是一个 bean 后处理器,可以在创建所有作业时注册它们。
以下示例显示了如何包含JobRegistryBeanPostProcessor对于作业
在 XML 中定义:
<bean id="jobRegistryBeanPostProcessor" class="org.spr...JobRegistryBeanPostProcessor">
<property name="jobRegistry" ref="jobRegistry"/>
</bean>以下示例显示了如何包含JobRegistryBeanPostProcessor对于作业
在 Java 中定义:
@Bean
public JobRegistryBeanPostProcessor jobRegistryBeanPostProcessor(JobRegistry jobRegistry) {
JobRegistryBeanPostProcessor postProcessor = new JobRegistryBeanPostProcessor();
postProcessor.setJobRegistry(jobRegistry);
return postProcessor;
}
尽管并非绝对必要,但
example 已经给出了一个id,以便它可以包含在 Child 中
contexts(例如,作为父 Bean 定义)并导致创建所有作业
那里也会自动注册。
自动作业注册器
这是一个生命周期组件,用于创建子上下文并从中注册作业
上下文。这样做的一个好处是,虽然
子上下文在 Registry 中仍然必须是全局唯一的,它们的依赖项
可以有 “natural” 名称。因此,例如,您可以创建一组 XML 配置文件
每个 Job 只有一个 Job 但都有不同的ItemReader使用
相同的 bean 名称,例如reader.如果所有这些文件都导入到同一上下文中,则
Reader 定义会相互冲突并覆盖,但是,使用 Automatic
registrar 的 intent 和未加密的 intent 的 x这使得集成
应用程序的单独模块。
以下示例显示了如何包含AutomaticJobRegistrar对于定义的作业
在 XML 中:
<bean class="org.spr...AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.spr...ClasspathXmlApplicationContextsFactoryBean">
<property name="resources" value="classpath*:/config/job*.xml" />
</bean>
</property>
<property name="jobLoader">
<bean class="org.spr...DefaultJobLoader">
<property name="jobRegistry" ref="jobRegistry" />
</bean>
</property>
</bean>以下示例显示了如何包含AutomaticJobRegistrar对于定义的作业
在 Java 中:
@Bean
public AutomaticJobRegistrar registrar() {
AutomaticJobRegistrar registrar = new AutomaticJobRegistrar();
registrar.setJobLoader(jobLoader());
registrar.setApplicationContextFactories(applicationContextFactories());
registrar.afterPropertiesSet();
return registrar;
}
registrar 具有两个必需属性:一个ApplicationContextFactory(从
方便的工厂 Bean)和JobLoader.这JobLoader负责管理子上下文的生命周期,并且
在JobRegistry.
这ApplicationContextFactory是
负责创建子上下文。最常见的用法
是(如前面的示例所示)来使用ClassPathXmlApplicationContextFactory.其中之一
这个工厂的特点是,默认情况下,它会复制一些
configuration down 从 parent context 到 child。因此,对于
实例中,您无需重新定义PropertyPlaceholderConfigurer或 AOP
配置,前提是它应与
父母。
您可以使用AutomaticJobRegistrar在
与JobRegistryBeanPostProcessor(只要您同时使用DefaultJobLoader).
例如,如果有工作,这可能是可取的
在主父上下文和子上下文中定义
地点。
JobOperator (作业作员)
如前所述,JobRepository提供对元数据的 CRUD作,并且JobExplorer在
元数据。但是,这些作在一起使用时最有用
执行常见监控任务,例如停止、重新启动或
总结 Job,这通常是由 Batch Operator 完成的。Spring Batch
在JobOperator接口:
public interface JobOperator {
List<Long> getExecutions(long instanceId) throws NoSuchJobInstanceException;
List<Long> getJobInstances(String jobName, int start, int count)
throws NoSuchJobException;
Set<Long> getRunningExecutions(String jobName) throws NoSuchJobException;
String getParameters(long executionId) throws NoSuchJobExecutionException;
Long start(String jobName, String parameters)
throws NoSuchJobException, JobInstanceAlreadyExistsException;
Long restart(long executionId)
throws JobInstanceAlreadyCompleteException, NoSuchJobExecutionException,
NoSuchJobException, JobRestartException;
Long startNextInstance(String jobName)
throws NoSuchJobException, JobParametersNotFoundException, JobRestartException,
JobExecutionAlreadyRunningException, JobInstanceAlreadyCompleteException;
boolean stop(long executionId)
throws NoSuchJobExecutionException, JobExecutionNotRunningException;
String getSummary(long executionId) throws NoSuchJobExecutionException;
Map<Long, String> getStepExecutionSummaries(long executionId)
throws NoSuchJobExecutionException;
Set<String> getJobNames();
}
上述作表示来自许多不同接口的方法,例如JobLauncher,JobRepository,JobExplorer和JobRegistry.因此,
提供了JobOperator (SimpleJobOperator) 具有许多依赖项。
以下示例显示了SimpleJobOperator在 XML 中:
<bean id="jobOperator" class="org.spr...SimpleJobOperator">
<property name="jobExplorer">
<bean class="org.spr...JobExplorerFactoryBean">
<property name="dataSource" ref="dataSource" />
</bean>
</property>
<property name="jobRepository" ref="jobRepository" />
<property name="jobRegistry" ref="jobRegistry" />
<property name="jobLauncher" ref="jobLauncher" />
</bean>以下示例显示了SimpleJobOperator在 Java 中:
/**
* All injected dependencies for this bean are provided by the @EnableBatchProcessing
* infrastructure out of the box.
*/
@Bean
public SimpleJobOperator jobOperator(JobExplorer jobExplorer,
JobRepository jobRepository,
JobRegistry jobRegistry,
JobLauncher jobLauncher) {
SimpleJobOperator jobOperator = new SimpleJobOperator();
jobOperator.setJobExplorer(jobExplorer);
jobOperator.setJobRepository(jobRepository);
jobOperator.setJobRegistry(jobRegistry);
jobOperator.setJobLauncher(jobLauncher);
return jobOperator;
}
从版本 5.0 开始,@EnableBatchProcessing注解自动注册作业作员 Bean
在应用程序上下文中。
| 如果您在作业存储库上设置了表前缀,请不要忘记在作业资源管理器中也设置它。 |
JobParametersIncrementer (作业参数增量器)
大多数JobOperator是
一目了然,您可以在界面的 Javadoc 中找到更详细的解释。但是,startNextInstance方法值得注意。这
方法始终会启动Job.
如果JobExecution和Job需要从头开始。与JobLauncher(这需要一个新的JobParameters对象触发新的JobInstance),如果参数与
任何先前的参数集,则startNextInstance方法使用JobParametersIncrementer绑定到Job以强制Job更改为
新建实例:
public interface JobParametersIncrementer {
JobParameters getNext(JobParameters parameters);
}
的合同JobParametersIncrementer是
给定一个 JobParameters 对象,它返回 “next”JobParametersobject 来增加它可能包含的任何必要值。这
策略很有用,因为框架无法知道
对JobParameters使其成为 “Next”
实例。例如,如果JobParameters是日期,下一个实例
应该创建,该值应增加 1 天或 1
周(例如,如果工作是每周)?任何
有助于识别Job,
如下例所示:
public class SampleIncrementer implements JobParametersIncrementer {
public JobParameters getNext(JobParameters parameters) {
if (parameters==null || parameters.isEmpty()) {
return new JobParametersBuilder().addLong("run.id", 1L).toJobParameters();
}
long id = parameters.getLong("run.id",1L) + 1;
return new JobParametersBuilder().addLong("run.id", id).toJobParameters();
}
}
在此示例中,键为run.id用于
区分JobInstances.如果JobParameters传入为 null,则可以是
假设Job以前从未运行
因此,可以返回其初始状态。但是,如果不是,则旧的
value 被获取,递增 1 并返回。
对于在 XML 中定义的作业,您可以将增量程序与Job通过incrementer属性,如下所示:
<job id="footballJob" incrementer="sampleIncrementer">
...
</job>对于在 Java 中定义的作业,您可以将增量程序与Job通过incrementer方法,如下所示:
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.incrementer(sampleIncrementer())
...
.build();
}
停止作业
最常见的用例之一JobOperator会正常停止
工作:
Set<Long> executions = jobOperator.getRunningExecutions("sampleJob");
jobOperator.stop(executions.iterator().next());
关闭不是立即的,因为没有办法强制
立即关闭,尤其是在执行当前处于
开发人员代码,例如
商业服务。但是,一旦控制权返回到
框架中,它会设置当前StepExecution自BatchStatus.STOPPED,保存它,并执行相同的作
对于JobExecution在完成之前。
中止作业
任务执行FAILED可以是
restarted(如果Job是可重新启动的)。状态为ABANDONED无法由框架重新启动。
这ABANDONEDstatus 也用于 STEP 中
executions 在重新启动的任务执行中将其标记为可跳过。如果
作业正在运行,并遇到已标记的步骤ABANDONED在上一个失败的任务执行中,它
继续执行下一步(由 Job Flow 定义确定
和步骤执行退出状态)。
如果进程宕机 (kill -9或 server
failure),则作业当然不会运行,但JobRepository具有
无法知道,因为在过程结束之前没有人告诉它。你
必须手动告诉它您知道执行失败
或应被视为已中止(将其状态更改为FAILED或ABANDONED).这是
一个商业决策,没有办法自动化它。更改
status 设置为FAILED仅当它是可重新启动的并且您知道重新启动数据有效时。